Existing LLM-based policy optimizers see only scalar rewards: that a policy scored 0.45,
but not whether the agent got stuck in a loop, fell into a hole on the third step, or
performed well on 19 out of 20 rollouts and failed catastrophically on one.
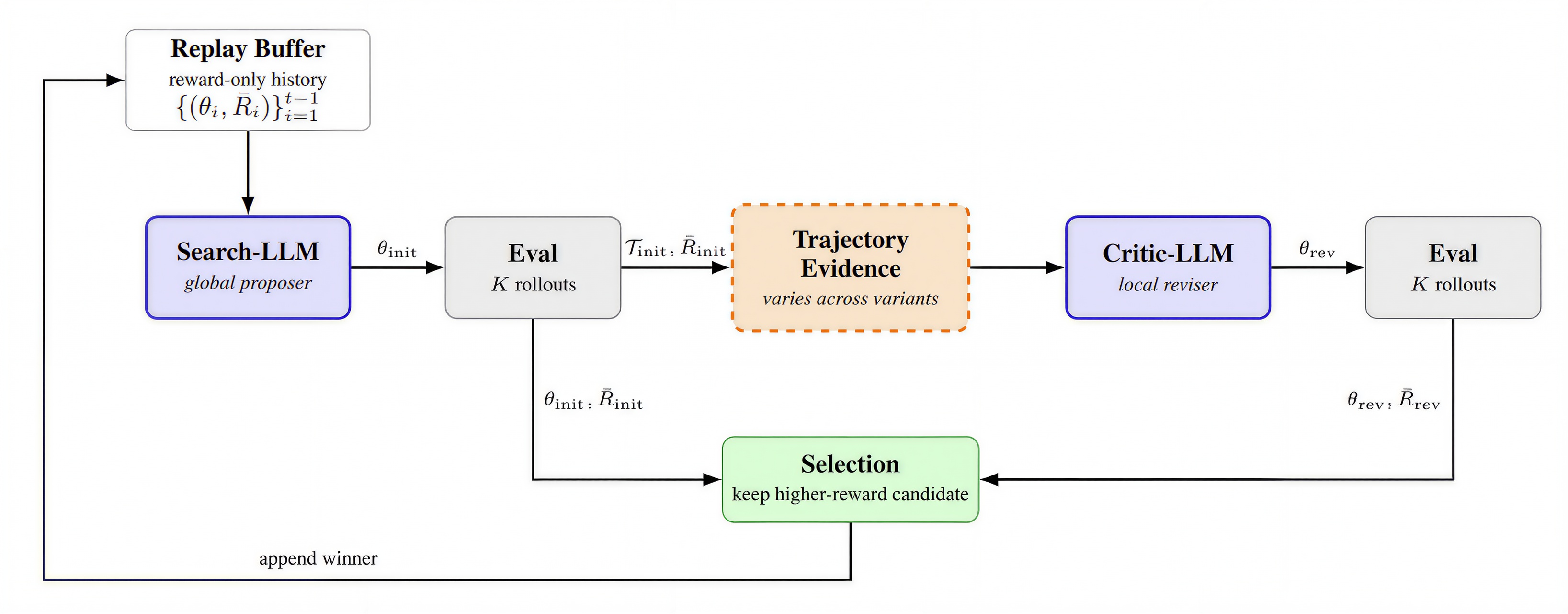
We propose Reflective Prompted Policy Optimization (R2PO), a two-stage LLM
framework for policy search over compact policy classes that augments scalar reward feedback
with trajectory-level behavioral evidence. A Search-LLM acts as a global policy
optimizer and proposes candidate policy parameters; the environment executes them; a
Critic-LLM then inspects the resulting rollouts and proposes targeted parameter
revisions grounded in observed states, actions, and rewards.
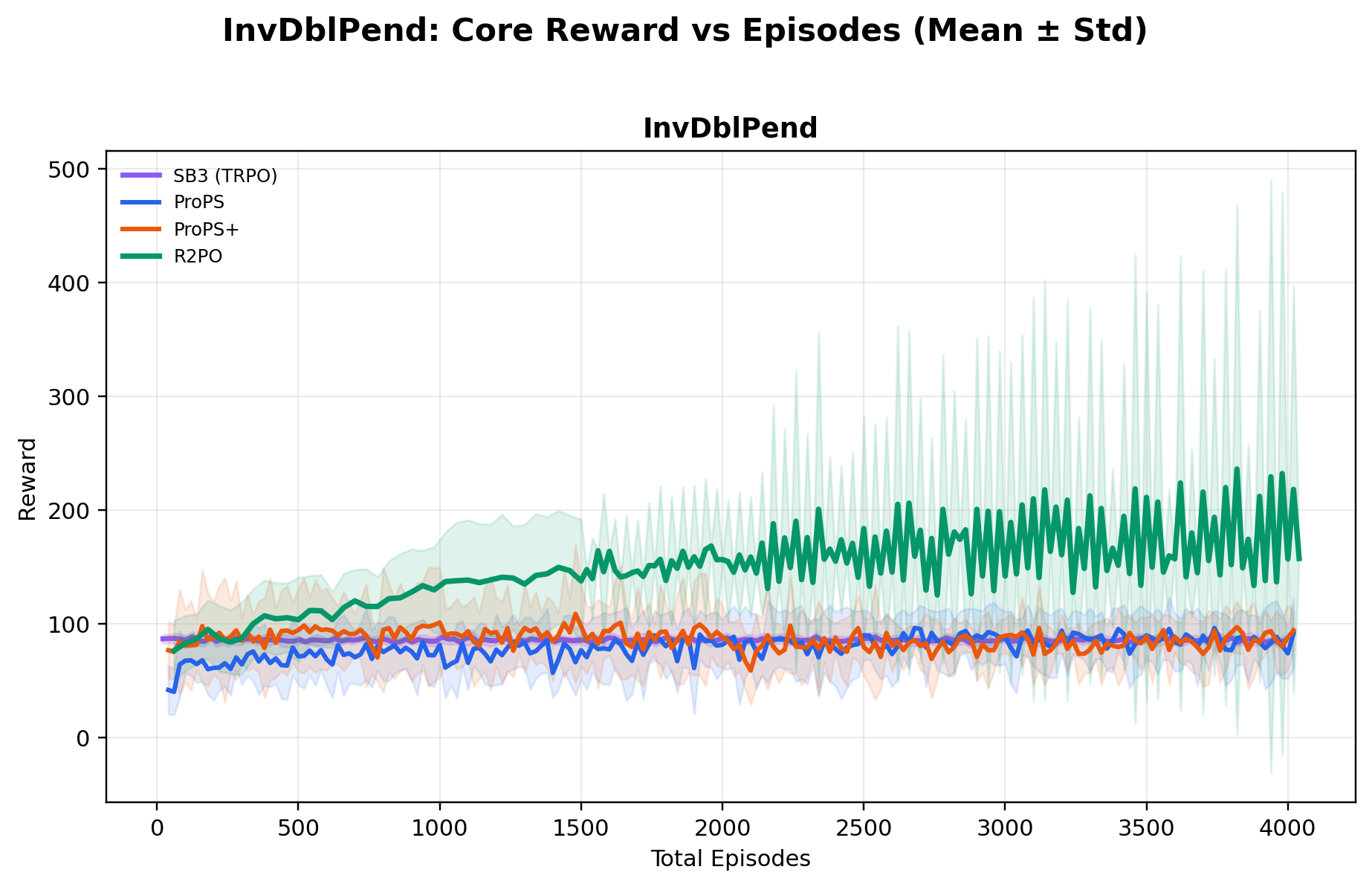
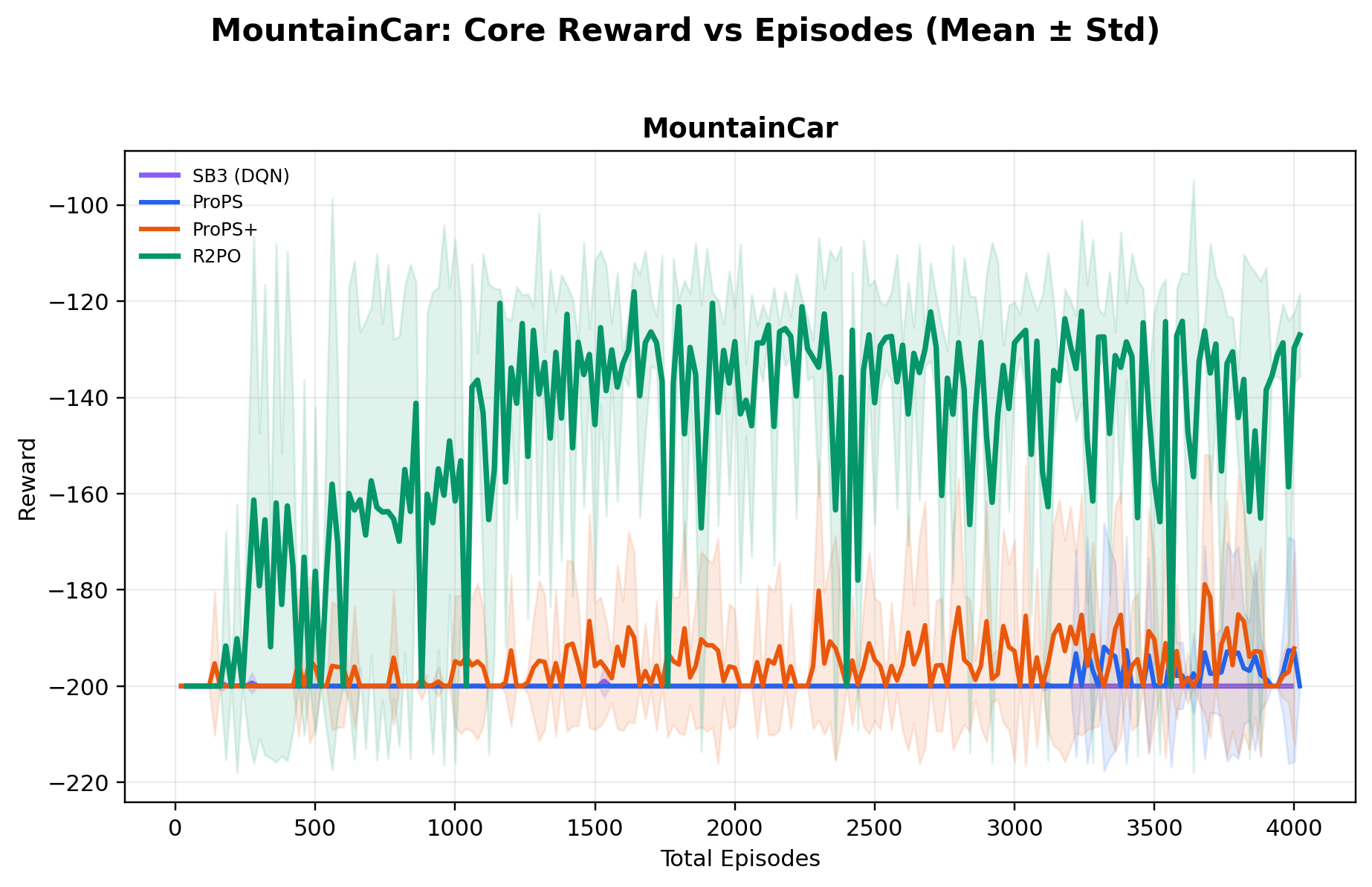
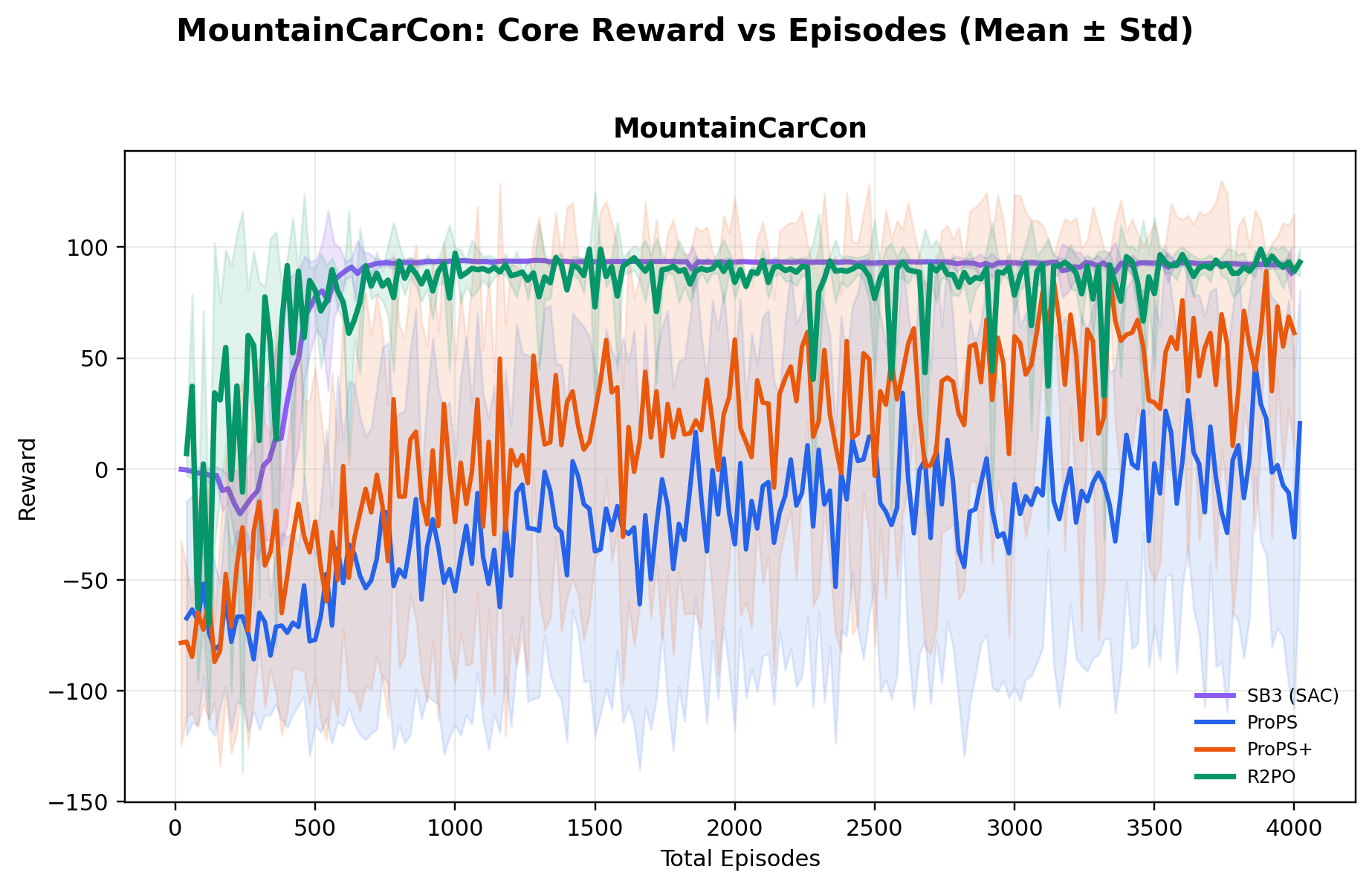
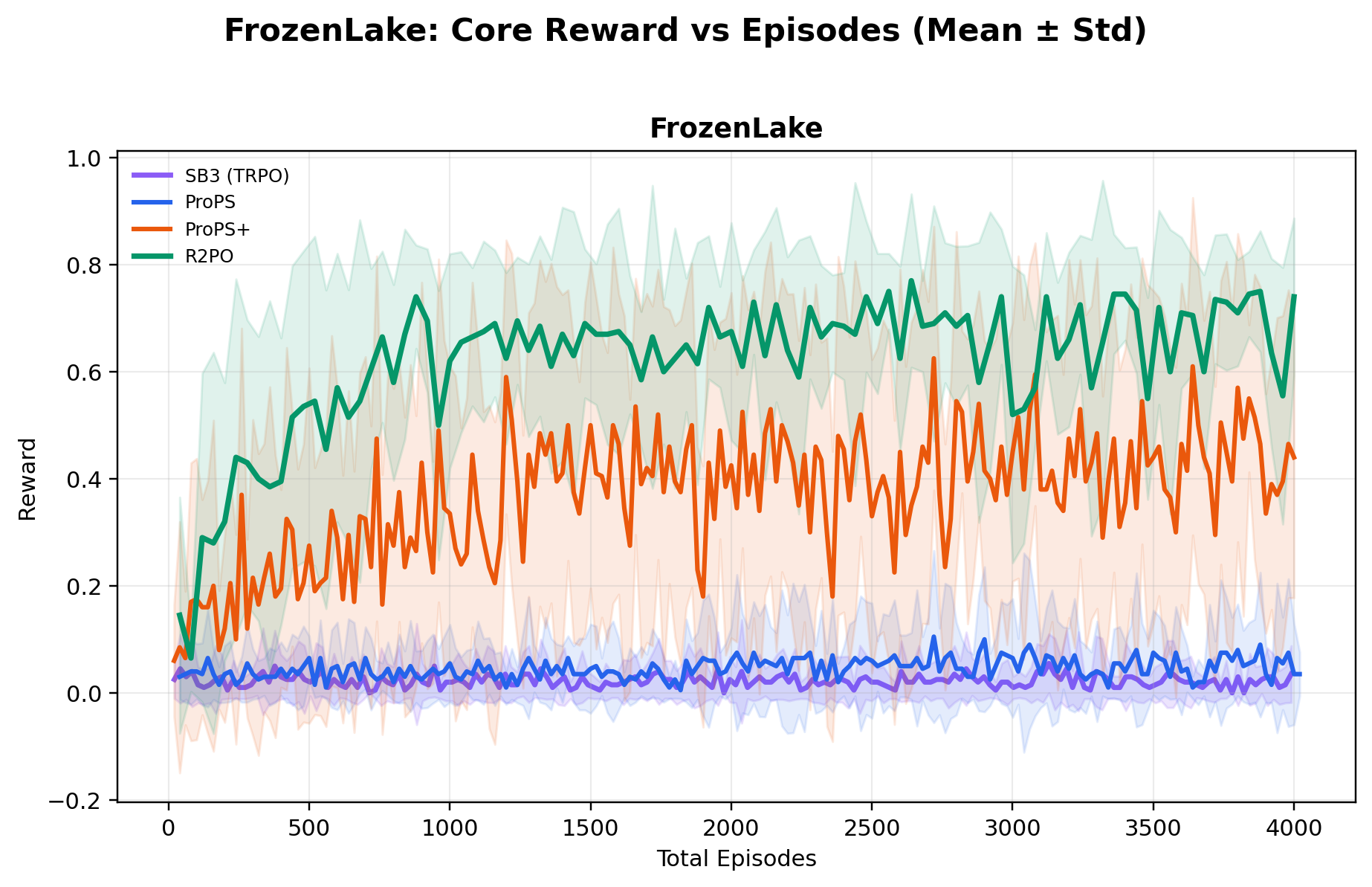
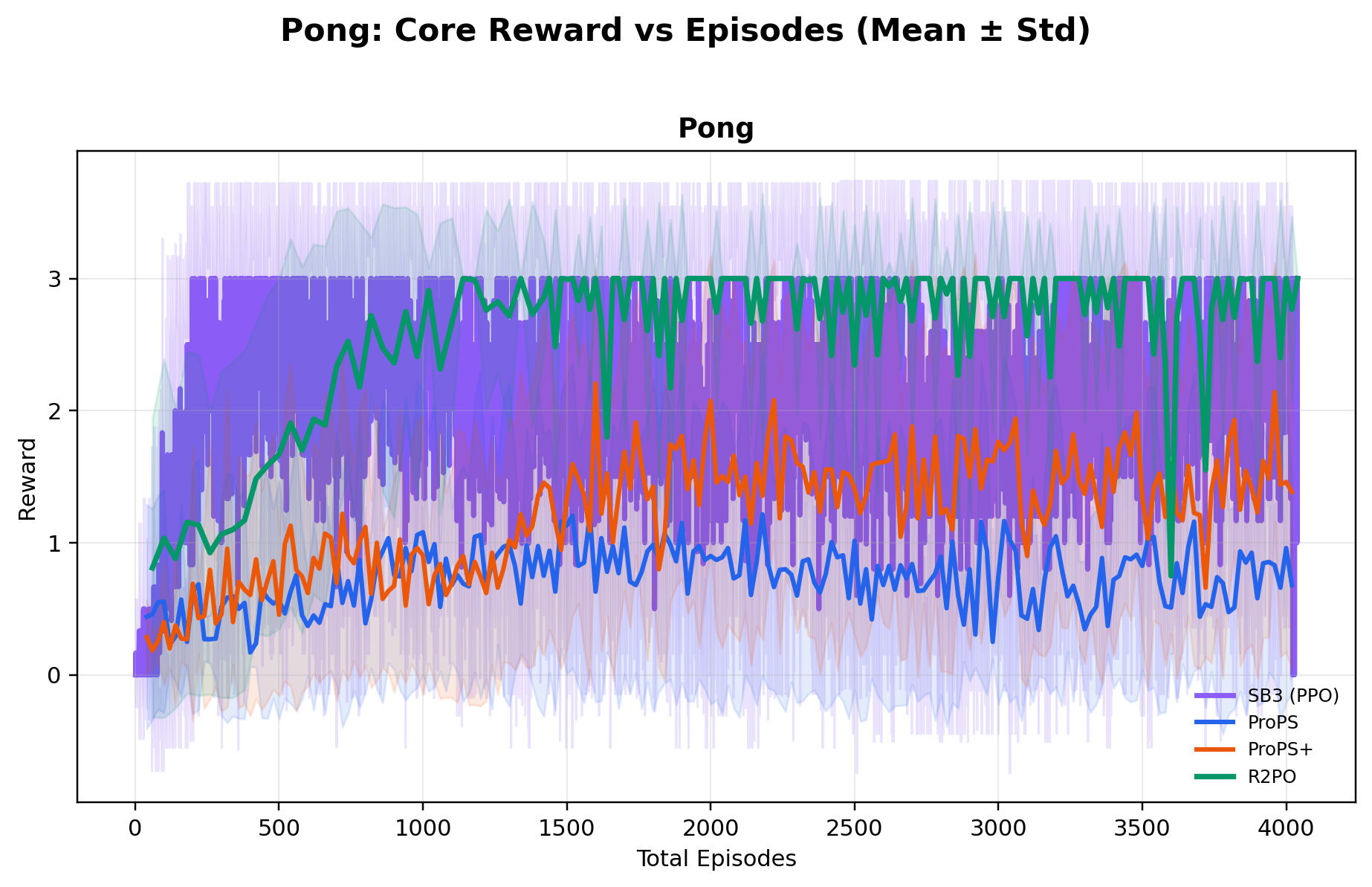
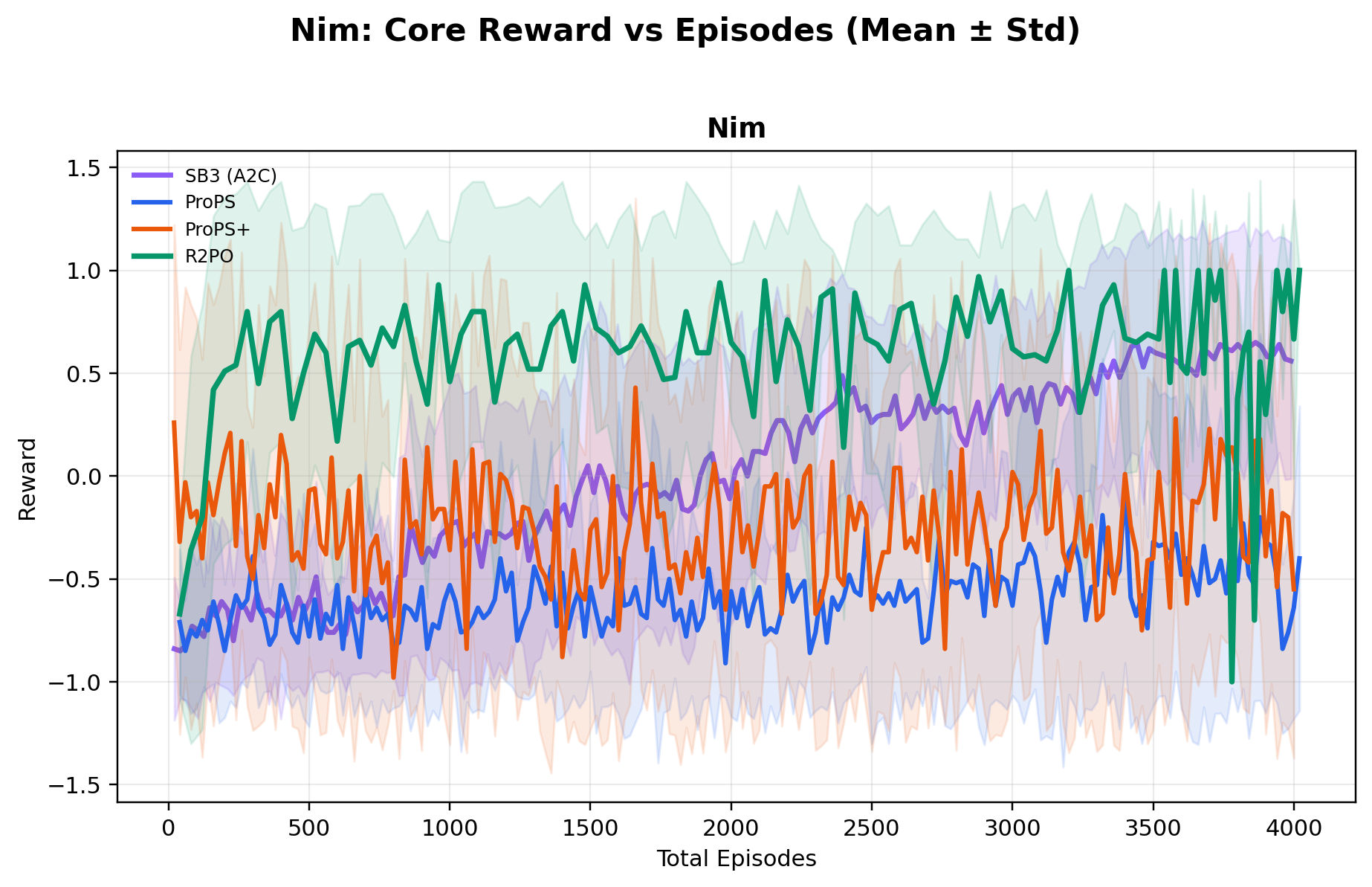
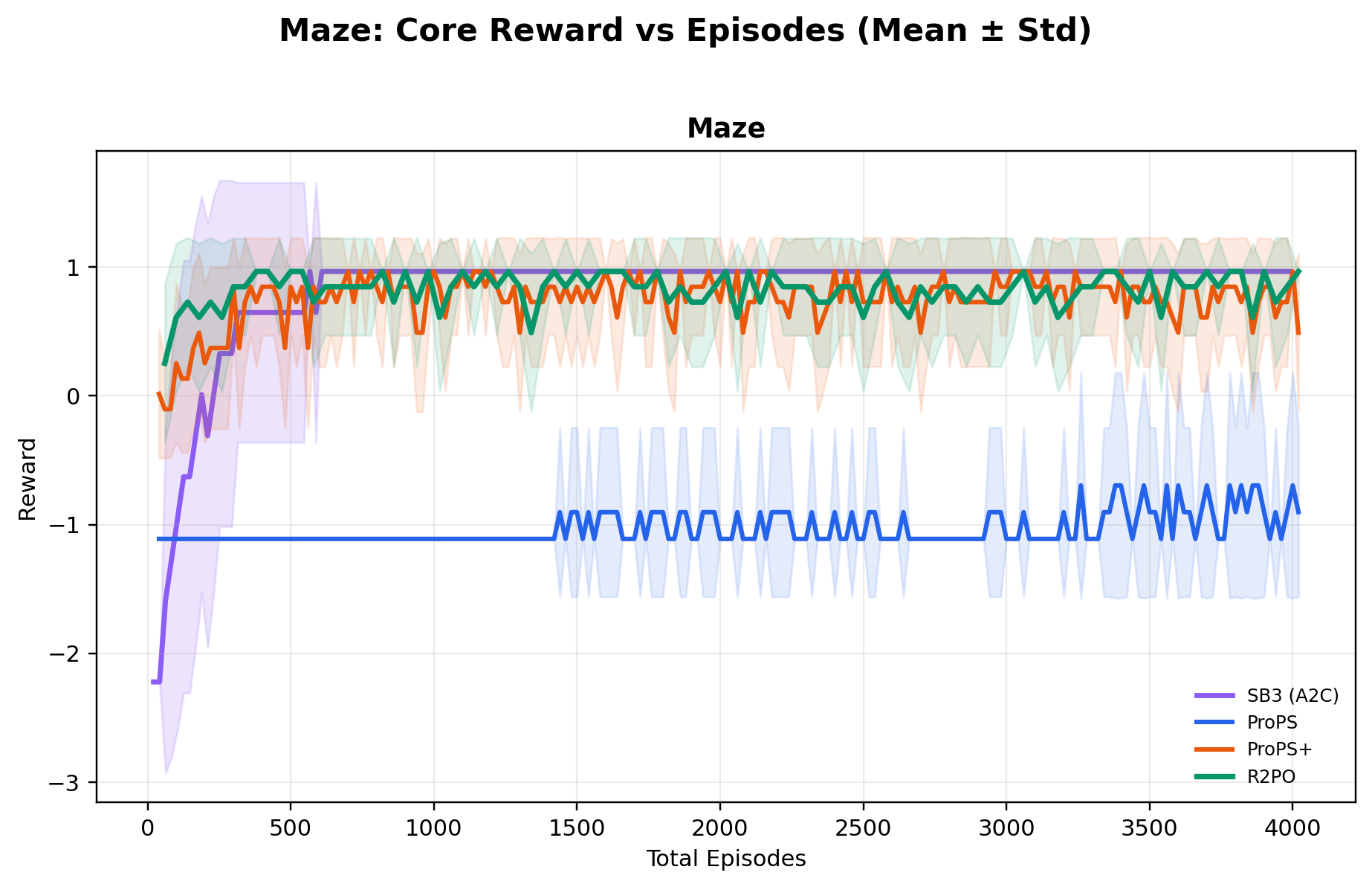
Across ten environments, ablations show R2PO's gains arise from a design that explicitly
separates global search from behavior-grounded revision and uses selection to filter
high-variance edits. We further identify a dominant failure mode, salience bias:
when presented with multiple rollouts, the Critic-LLM fixates on improving a single failure
even when most trajectories succeed. In a three-trajectory variant, this behavior explains
76.6% of regressions on CartPole. R2PO mitigates this by reasoning over aggregate rollout
statistics, median-trajectory selection, and a revision rule.
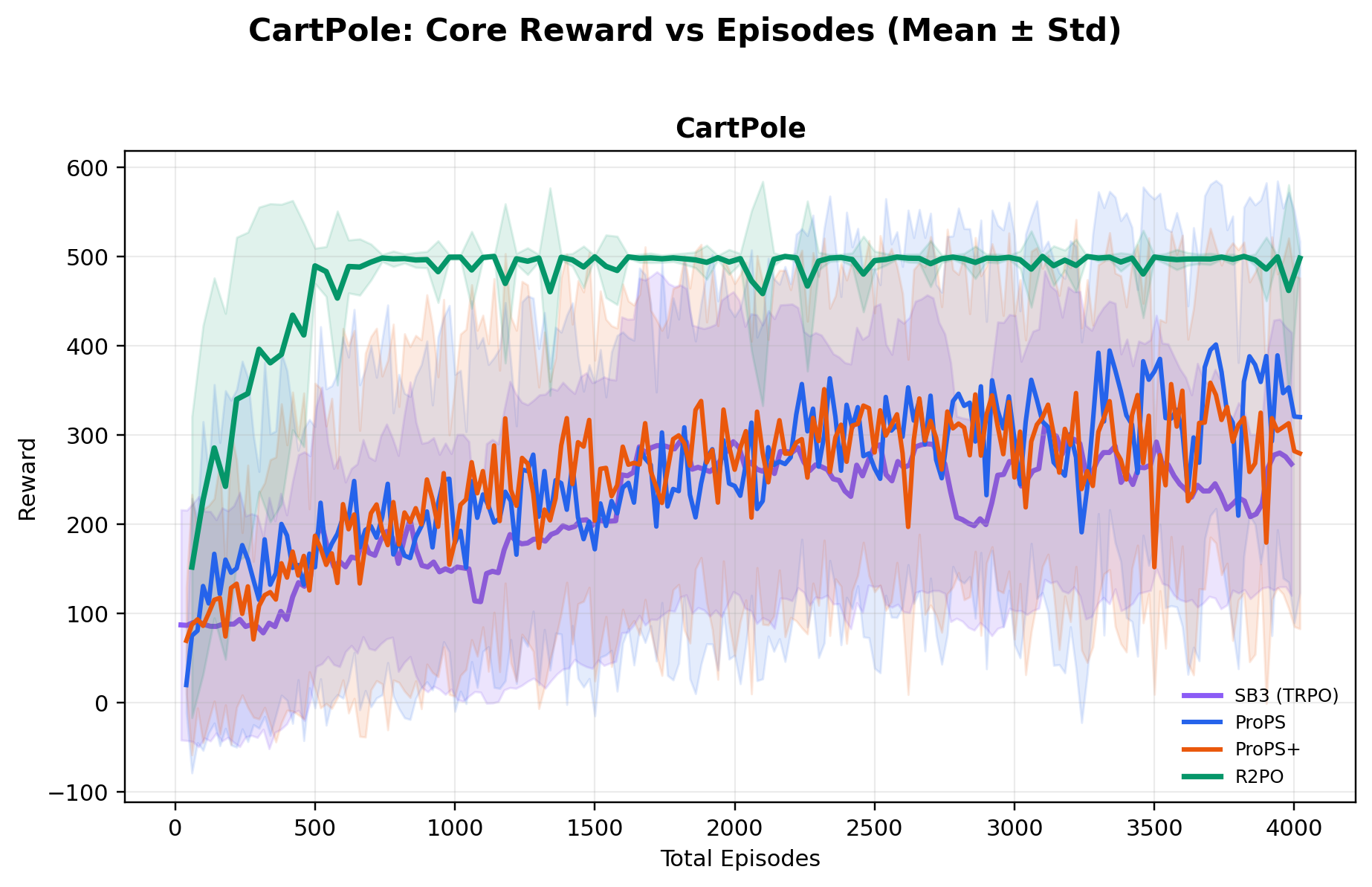
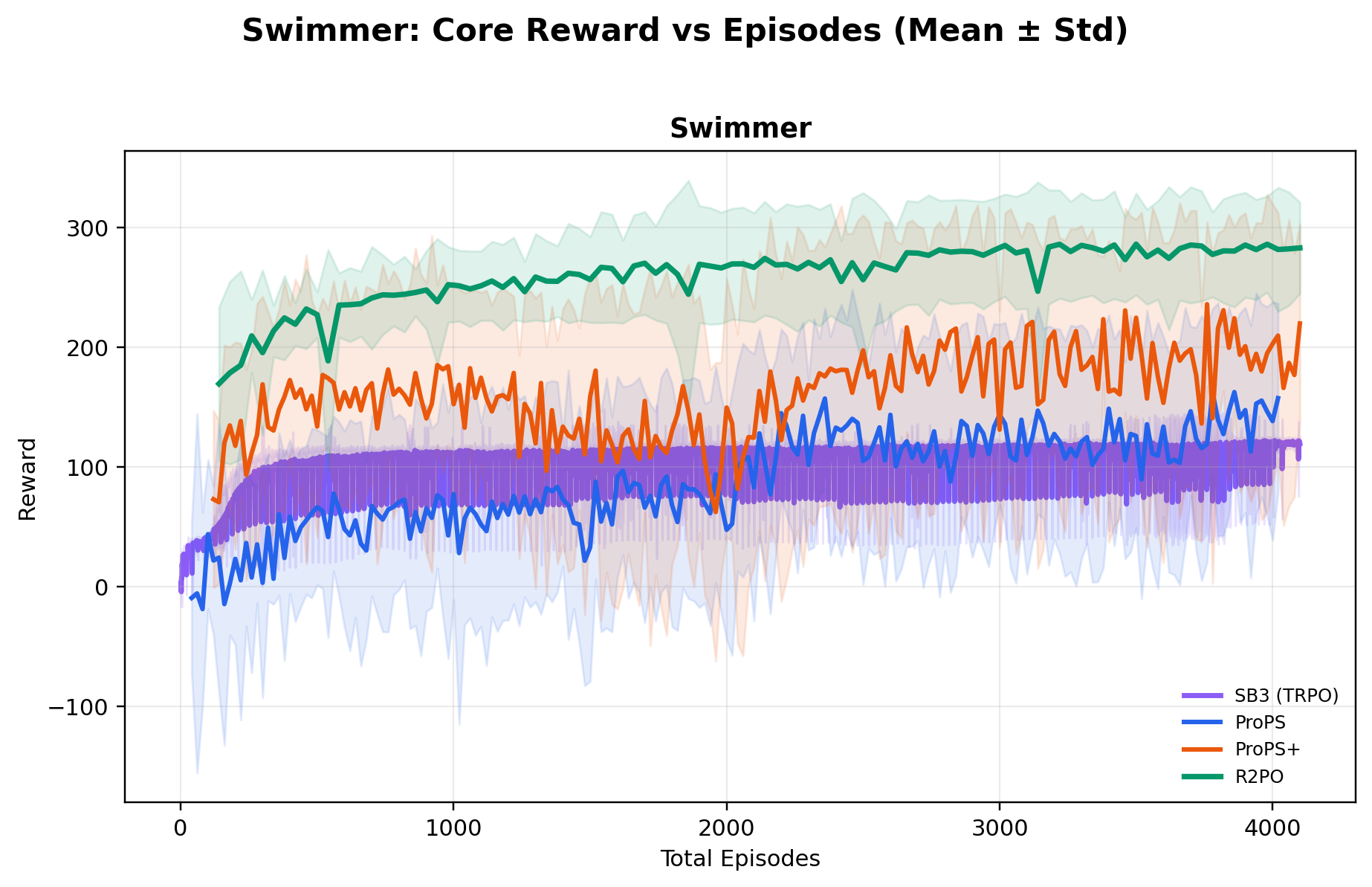
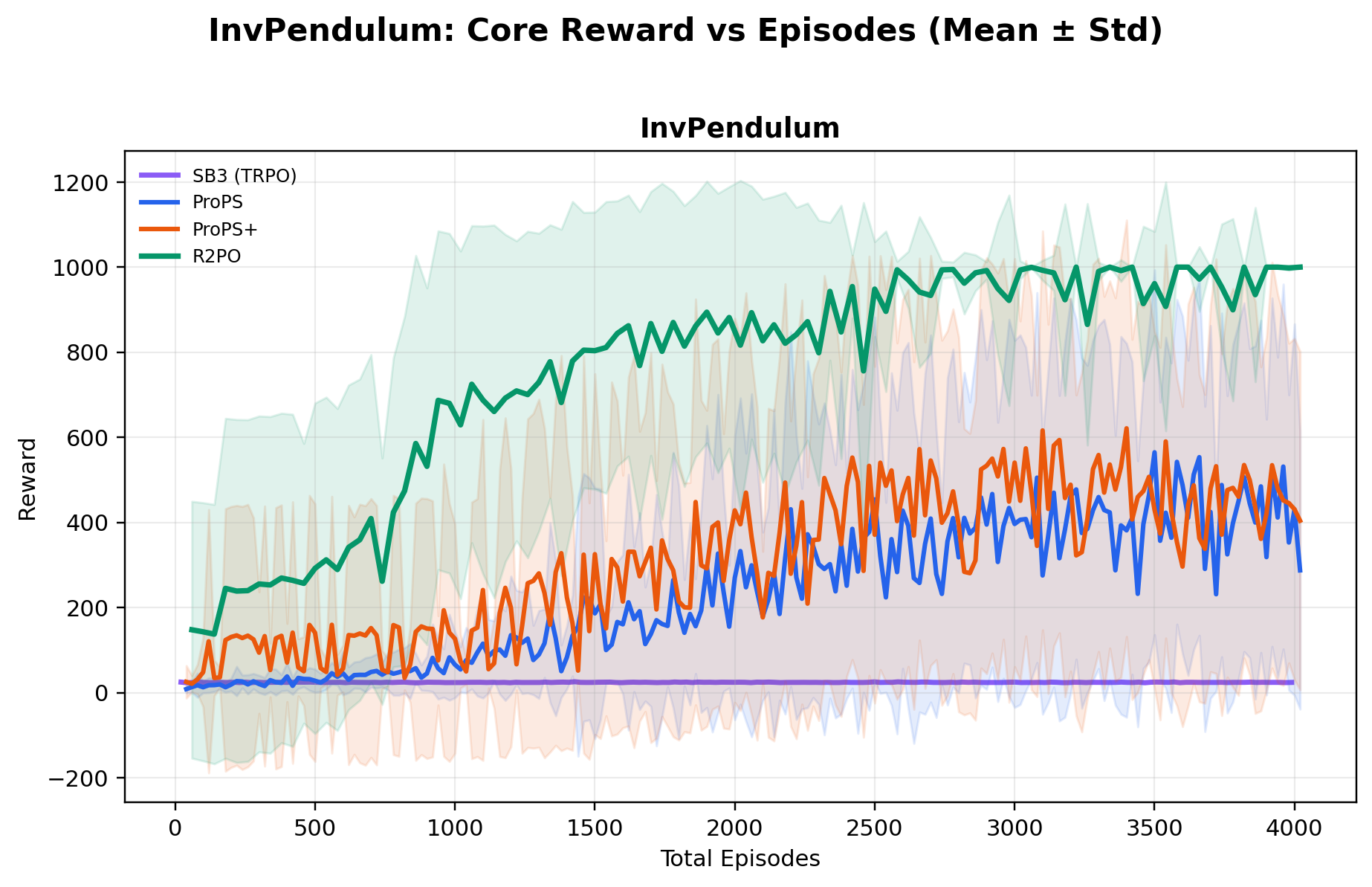
Using a relatively small open-weight 20B-parameter model, R2PO achieves the highest mean
best reward across all ten environments, while reaching near-optimal performance
substantially earlier in training (e.g., near-maximum CartPole reward within ~500 episodes),
and training far more stably than both deep RL and prior LLM-based methods.